
공부일기
DL/ 손실 곡선, 검증 손실, Dropout, 모델 저장, 콜백(ModelCheckpoint, EarlyStopping) 본문
손실 곡선을 그려보며 최고의 신경망 모델을 얻어보자.
손실 곡선
계속 새로 모델을 만드는것이 귀찮으니까 모델 만드는 것을 함수로 지정하겠다.
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Input(shape=(28,28)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model
코드 보면 알듯이 층을 넣어주면 그 층을 입력층과 출력층 사이에 추가하는거당.
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history=model.fit(train_scaled, train_target, epochs=5, verbose=0)
훈련된 model 객체를 history에다가 넣어줬다. fit() 메서드는 History 객체를 반환한다. 여기에는 훈련 중 계산한 지표 즉, 손실과 정확도 값 등이 들어있다.
print(history.history.keys())dict_keys(['accuracy', 'loss'])
history 객체에는 history 딕셔너리가 들어있다. keys를 확인해보면 뭐가 들어있는지 알 수 있다.
이 값들을 활용해서 그래프를 그려보자!!
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()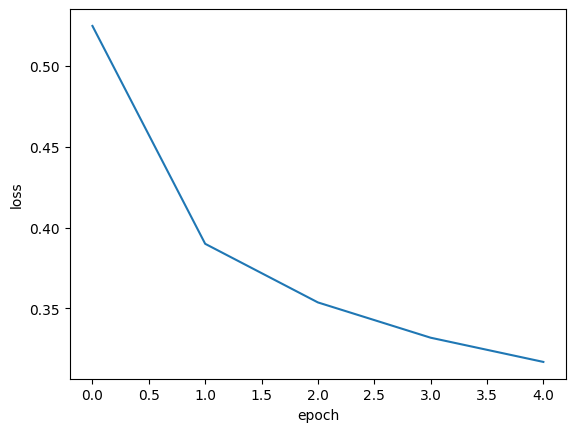
5번의 에포크를 수행했으니 0,1,2,3,4 로 기록된다.
몇번의 에포크를 해야지 최적의 에포크가 될까? 즉, 과대적합과 과소적합을 어떻게 하면 막을 수 있지??
가보자잇
검증 손실
우리는 훈련세트에 대한 점수뿐만 아니라 검증세트에 대한 점수도 확인해야할 것이다. 그래야지 확인하지?
validation_data 매개변수
model=model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history=model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
검증 데이터를 전달하기 위해서 validation_data 매개변수에 검증할 입력값과 타깃값을 넣어준다.
verbose=0이라고 하는거는 밑에 뜨는 프로그래스 바를 생략시키겠다는 뜻입니당.
history 안에는 어떤 키들이 있을까요?ㅇ
print(history.history.keys())dict_keys(['accuracy', 'loss', 'val_accuracy', 'val_loss'])
오! 검증손실과 검증정확도가 생겼다리~
그래프를 그려봅시다!
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='val')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
검증손실이 상승하는 지점을 최대한 뒤로 늦춘 에포크가 최적의 에포크이지 않을까?
우선은 'adam' 옵티마이저를 적용시켜서 다시 훈련시켜보자잉!
model = model_fn()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history=model.fit(train_scaled, train_target, verbose=0, epochs=20, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='val')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
오우 과대적합이 훨씬 많이 줄었넹 ㄷㄷ
추가적인 규제에 대해서 알아보자!
드롭 아웃 층 추가(Dropout)
드롭아웃은 모델 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼버린다. 얼마나 많은 뉴런을 드랍할지는 우리가 하이퍼파라미터로 정하면 된다.
드롭 아웃을 층처럼 추가하지만 훈련되는 모델 파라미터는 존재하지 않는다. 한번 확인해보자잉
model=model_fn(keras.layers.Dropout(0.3))
model.summary()Model: "sequential_4"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ flatten_4 (Flatten) │ (None, 784) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_8 (Dense) │ (None, 100) │ 78,500 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 100) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_9 (Dense) │ (None, 10) │ 1,010 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 79,510 (310.59 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)
역시 dropout층에서는 아무런 파라미터도 훈련되지 않는군. 0.3을 준거는 30%정도를 드롭아웃하겠다는 뜻이당. 손실값 확인해봅시당
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history=model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='val')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()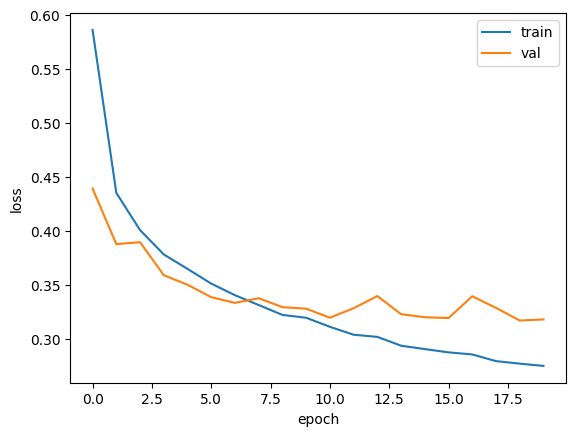
과대적합이 확실히 줄었다. 10번째 에포크가 제일 좋아보이는거 같은데.. 큐!
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history=model.fit(train_scaled, train_target, epochs=10, verbose=0, validation_data=(val_scaled, val_target))
모델 저장하기
save() 메서드
케라스 모델은 모델의 구조와 파라미터를 함께 저장하는 save() 메서드를 제공한다. 요건 .keras 확장자를 가진 파일에 필요한 모든 정보를 압축하여 저장한다.
save_weights() 메서드
이 메서드는 훈련 모델의 파라미터만 저장한다. 확장자는 weights.h5로 끝난다.
model.save('model-whole.keras')
model.save_weights('model.weights.h5')
이 저장된 애들을 사용해서 모델을 생성해봅시당잉
저장된 모델로 초기화 시켜주기(load_model)
model = keras.models.load_model('model-whole.keras')
model.evaluate(val_scaled, val_target)375/375 ━━━━━━━━━━━━━━━━━━━━ 2s 3ms/step - accuracy: 0.8807 - loss: 0.3341
[0.3405589163303375, 0.8786666393280029]
아주 성공적이군.
저장된 파라미터를 넣어주기(load_weights)
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model.weights.h5')
save_weights와 쌍으로 다니는 load_weights를 사용해서 이름을 넘겨준다.
지금까지 한 내용들을 정리해보면,
최적의 모델을 찾기 위해서 모델을 20번의 에포크동안 실행 시키고,
손실함수를 그려서 최적의 지점처럼 보이는 에포크를 구해서,
다시 모델을 그만큼의 에포크로 훈련시켰다.
굳이 이렇게 여러번 할 필요가 있을까??
드디어 너란 놈이 나오는구나... 콜백! 오레노 턴~
콜백
콜백은 훈련 과정 중간에 다른 작업을 수행할 수 있도록 해주는 클래스이다.
fit() 메서드의 callbacks 매개변수에 리스트로 전달하여 사용한다.
ModelCheckpoint
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.keras', save_best_only=True)
model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb])
ModelCheckpoint은 매 에포크마다 모델을 저장한다. 저장될 파일 이름을 'best-model.keras'로 넣어줬당.
save_best_only = True 매개변수를 통해 가장 낮은 검증 손실을 만드는 모델을 저장할 수 있다!
checkpoint_cb에 ModelCheckpoint객체를 담아준다.
자 그럼 best-model.keras에 담긴 모델로 load_model 해보장
model = keras.models.load_model('best-model.keras')
model.evaluate(val_scaled, val_target)375/375 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.8851 - loss: 0.3198
[0.3203848600387573, 0.8846666812896729]
상당히 점수가 좋고, 편하다!!
하지만 근본적인 원인인 20번 에포크하는것을 막진 못한다. 그렇다면 조기종료를 해보자!!!
EarlyStopping
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.keras', save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history=model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
EarlyStopping 콜백의 patience 매개변수는 검증점수가 몇번까지 향상이 되지 않아도 참고 견딜지 정해주는 횟수이다. 위의 코드는 3번 연속 나아지지 않으면 조기종료시킨다는 뜻이다.
restore_best_weights 는 가장 낮은 검증 손실을 낸 모델 파라미터를 되돌려준다. 이를 통해 몇번째 에포크에서 훈련이 중지되었는지 살펴봅시다.
print(early_stopping_cb.stopped_epoch)14
14번째 에포크에서 멈췄따!! 그 말인 즉슨, 12번, 13번, 14번 에포크 동안 점수가 상승하지 않았다는 뜻이니 최상의 모델이 11번째 에포크에 존재(patience가 3) 한다는 뜻이다. 그래프로 그려보자
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='val')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()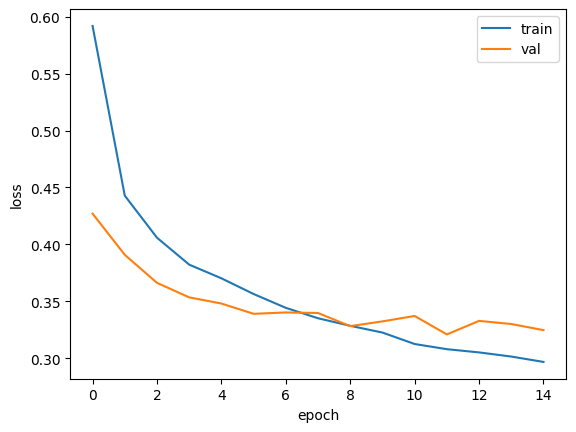
정말 놀랍다. 귀신같다. epoch가 11일때 검증점수가 제일 낮은것을 확인할 수 있다.
이 모델에 대한 검증 점수 최종 확인하면은!
model.evaluate(val_scaled, val_target)375/375 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.8878 - loss: 0.3211
[0.32090646028518677, 0.8845000267028809]
다양한 콜백에 대해서도 알아봤다.
'DL' 카테고리의 다른 글
| DL/ keras, 심층 신경망, 렐루 함수, 옵티마이저 (0) | 2026.01.29 |
|---|
