
공부일기
DL/ keras, 심층 신경망, 렐루 함수, 옵티마이저 본문
Keras와 패션 MNIST 데이터셋을 활용하여 인공신경망, 딥러닝에 대한 기초를 다져보겠습니다.
Keras로 MNIST 데이터셋 load해오기
import keras
(train_input, train_target), (test_input, test_target)=keras.datasets.fashion_mnist.load_data()
keras.datasets 아래에 있는 fashion_mnist 데이터를 load_data() 함수를 사용해서 훈련데이터와 테스트 데이터로 나눠서 가져와 준다.
print(train_input.shape, train_target.shape)(60000, 28, 28) (60000,)
훈련데이터에는 이미지의 크기가 28X28인 패션 이미지 60000개가 들어있는것을 알 수 있다.
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1,10,figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
subplots(1, 10) : 1행 10열짜리 그림판을 만든다
fig : 전체 그림(도화지)
axs : 각 칸(축, axes) 들의 배열, axs는 이렇게 생김: axs[0], axs[1], ..., axs[9]
figsize: 전체 그림의 크기 (가로, 세로)
imshow : 행렬(숫자 배열)을 이미지처럼 보여주는 함수
축(axis) 제거
print(train_target[:10])[9 0 0 3 0 2 7 2 5 5]
훈련 데이터들 각각의 샘플을 1차원 배열로 만들장.
train_scaled = train_input/255.0
train_scaled = train_scaled.reshape(-1, 28*28)
픽셀의 경우 0~255 사이의 정수값을 가지는데 255로 나누어서 0~1사이의 값으로 정규화 시켜준다. 그리고 reshape() 메서드를 사용해서 28*28 크기의 픽셀을 1차원으로 펴준다.
인공신경망으로 가보장!
인공신경망
인공신경망에서는 교차검증을 사용하지 않고 검증 세트를 별도로 덜어내어 사용한다.
1. 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적이다.
2. 교차 검증을 수행하기에는 너무 오랜 시간이 걸린다.
때문에 train_test_split으로 사용해서 덜어주겠다용
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
입력층 추가
inputs = keras.layers.Input(shape=(784,))
입력층을 inputs 변수 안에 선언해주었다. Input() 함수의 shape 매개변수에 28*28=784 개의 픽셀이 입력값이므로 크기를 지정해주었다.
밀집층 추가(활성화 함수 설정)
dense = keras.layers.Dense(10, activation='softmax')
첫번째로 10을 넣어주는데 이는 뉴런의 개수를 지정해준것이다. 패션아이템의 종류가 10개가 있기 때문.
뉴런에서 출력되는 값을 무슨 활성화 함수로 바꿔줄 지를 다중분류이기 때문에 activation 변수에 'softmax' 함수를 넣어준다.
신경망 모델 생성
model = keras.Sequential([inputs, dense])
Sequential 클래스를 사용해서 앞서 만든 입력층과 밀집층을 순서대로 넣어준다. 그럼 이제 이 모델로 패션 아이템 분류를 해보자잉
모델 컴파일
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
손실함수의 종류를 반드시 지정해야한다. 현재 손실함수는 'sparse_categorical_crossentropy'이다.
손실함수(loss)
- 이진분류: 'binary_crossentropy'
- 다중분류: 'categorical_crossentropy'
원래 다중분류에서 크로스 엔트로피 손실 함수를 사용하려면 정수로 된 타깃값을 원-핫 인코딩으로 변환해야한다. 하지만 케라스에서는 정수로 된 타깃값을 원-핫 인코딩으로 바꾸지 않고 그냥 사용할 수 있다. 그냥 타깃 정수값 그대로 크로스 엔트로피 손실을 계산하는 것이 바로 'sparse_categorical_crossentropy' 이다.
지표 지정해주기(metrics)
케라스는 모델이 훈련할 때 기본적으로 에포크마다 손실 값을 출력해주는데, metrics에 지표를 추가 지정해주면 해당 지표에 관한 값도 출력해준다. 'accuracy'는 정확도에 관한 지표이다.
모델 훈련하기(fit())
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 5s 2ms/step - accuracy: 0.7424 - loss: 0.7773
Epoch 2/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8366 - loss: 0.4799
Epoch 3/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8442 - loss: 0.4513
Epoch 4/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - accuracy: 0.8507 - loss: 0.4366
Epoch 5/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8529 - loss: 0.4358
<keras.src.callbacks.history.History at 0x7c8489519610>
에포크 마다 걸린 시간과 정확도, 손실 값을 출력해준다.
5번 반복에 정확도가 85% 정도 되는 것을 확인할 수 있다.
검증세트에 대한 점수도 확인해볼까??
모델의 성능 평가하기(evaluate())
model.evaluate(val_scaled, val_target)375/375 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.8471 - loss: 0.4427
[0.4481904208660126, 0.8453333377838135]
fit()과 비슷한 결과가 나온다. 훌륭하구나.
이제 성능을 더 높이기 위해서 은닉층을 추가해보겠다.
심층 신경망(은닉층 추가하기)
은닉층은 입력층과 출력층 사이에 있는 모든 층을 일컫는 층이다.
은닉층에는 활성화 함수를 자유롭게 붙일 수 있따.
시그모이드 함수를 사용한 은닉층을 추가해봅시다.
inputs=keras.layers.Input(shape=(784,))
dense1 = keras.layers.Dense(100, activation='sigmoid')
dense2 = keras.layers.Dense(10,activation='softmax')
model = keras.Sequential([inputs, dense1, dense2])
dense1은 은닉층이고 100개의 뉴런을 가진 밀집층이다. 밀집층의 뉴런 개수는 출력층의 뉴런 개수보다는 많아야한다. 만약 출력층이 10개인데 은닉층의 뉴런 개수가 10개보다 작으면 제대로 된 정보 전달이 이루어지지 않는다.
이 모델의 정보를 알아보자.
모델 정보 출력하기(summary())
model.summary()Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ dense_1 (Dense) │ (None, 100) │ 78,500 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 10) │ 1,010 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 79,510 (310.59 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)
그림으로도 이쁘게 출력된다.
은닉층의 출력 크기는 (Nonde,100)인데, 첫번째 차원은 샘플의 개수를 나타낸다. 샘플 개수가 아직 정의가 안되어있어서 None이다. 케라스의 fit()은 미니배치 경사 하강법을 사용한다. 기본 미니배치의 크기는 32개인데 fit() 메서드의 batch_size 매개변수로 바꿀 수 있따. 여긴 샘플 개수를 고정하지 않고 유연하게 대응시키기 위해 None으로 되어있다.
두번째 차원은 뉴런의 개수이다. 샘플의 784개의 픽셀값이 은닉층을 통과하면서 100개의 특성으로 압축된다.
Param은 모델 파라미터 개수가 출력된다. Dense 층이므로 784*100 + 절편*100 = 78,500 이 나온다.
출력층도 동일하다.
summary() 메서드의 마지막에는 총 파라미터 수와 훈련되는 파라미터 수가 출력되고, Non-tainable params로 훈련에 사용되지 않는 파라미터 수도 출력해준다.
층을 추가할때는 add() 메서드를 사용해서 추가할 수 도 있따.
model = keras.Sequential()
model.add(keras.layers.Input(shape=(784,)))
model.add(keras.layers.Dense(100, activation='sigmoid'))
model.add(keras.layers.Dense(10,activation='softmax'))
이제 이 모델을 훈련시켜보자!!
컴파일 까먹지 말기!!!
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 5s 2ms/step - accuracy: 0.7578 - loss: 0.7630
Epoch 2/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8462 - loss: 0.4221
Epoch 3/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8624 - loss: 0.3767
Epoch 4/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - accuracy: 0.8684 - loss: 0.3603
Epoch 5/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8770 - loss: 0.3364
<keras.src.callbacks.history.History at 0x7f225a1da2d0>
위에서 은닉층 추가 안했을때는 85%정도였지만 현재는 87%정도나 나온다.
Flatten 층에 대해서 알아본 후 은닉층에 다른 활성화 함수를 사용해보자
Flatten 층
Flatten 클래스는 입력 차원을 모두 일렬로 펼치는 역할을 해준다. 성능을 위해서 기여하는 바는 없지만 따로 reshape 하지않고 원본 사이즈 그대로 지정을해도 1차원으로 펼쳐준다.
렐루 함수
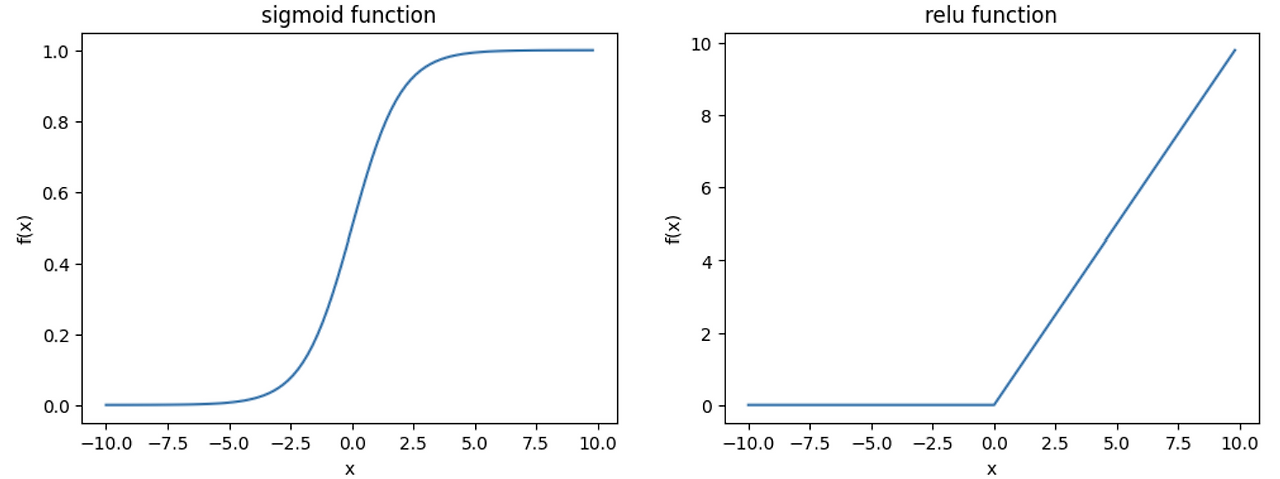
시그모이드 함수는 오른쪽과 왼쪽 끝으로 갈수록 누워있다. 즉 기울기가 0에 가까워지는데, 쉽게 말하면 은닉층을 여러개 추가해도 업데이트가 거의 이루어지지 않는다. 반면 렐루함수는 양수구간에서 기울기가 1로 계속 유지가 된다.
뉴런에서 나온 값 z값이 0보다 크면 z를 렐루에 대입, 0보다 작다면 0을 대입한다.
모델 생성해봅시다
model = keras.Sequential()
model.add(keras.layers.Input(shape=(28,28)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10,activation='softmax'))
summary 결과는?
model.summary()Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ flatten (Flatten) │ (None, 784) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 100) │ 78,500 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_3 (Dense) │ (None, 10) │ 1,010 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 79,510 (310.59 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)
Flatten()을 사용했으므로 훈련 데이터를 reshape하지않은 날것으로 준비해도 된다!!
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled= train_input/255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
자 그럼 이제 컴파일과 fit 해보자!
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - accuracy: 0.7645 - loss: 0.6761
Epoch 2/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8529 - loss: 0.4096
Epoch 3/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 4s 3ms/step - accuracy: 0.8708 - loss: 0.3595
Epoch 4/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - accuracy: 0.8783 - loss: 0.3366
Epoch 5/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8826 - loss: 0.3230
<keras.src.callbacks.history.History at 0x7f21bb6f1250>
이번엔 88% 정도의 성능이 나온다. 점점 성능이 늘고 있다. 검증점수도 확인해보장
model.evaluate(val_scaled, val_target)375/375 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.8727 - loss: 0.3558
[0.3557646870613098, 0.8737499713897705]
굳,,,
그럼 이제 인공신경망의 하이퍼파라미터인 옵티마이저에 대해서 알아보자.
옵티마이저(모멘텀 최적화, 적응적 학습률)
모델을 compile 할 때 케라스는 기본 경사 하강법 알고리즘인 RMSprop을 사용한다. 케라스는 다양한 경사 하강법 알고리즘을 제공하는데 이들을 옵티마이저라고 한다.
우선 기본 옵티마이저인 'sgd'
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
이렇게도 쓸 수 있다.
sgd=keras.optimizers.SGD(learning_rate=0.1)
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
SGD 클래스의 기본 학습률(learning_rate) 값은 0.01이다.
learning_rate는 경사하강법에서 손실을 줄이기 위해 가중치를 얼마나 크게 수정할지 결정하는 값이다.
sgd=keras.optimizers.SGD(momentum=0.9, nesterov=True)
momentum은 이전 이동 방향을 얼마나 유지할지 정해준다. 관성.
모멘텀의 기본값은 0 인데 이름 0보다 큰 값으로 지정하면 모멘텀 최적화가 된다.
nesterov를 True로 두면 네스테로프 모멘텀 최적화를 사용하는데 모멘텀 최적화를 두번 반복하는거다.
모델이 최적점에 가까워질수록 학습률(learning_rate)을 낮출 수 있따. 이런 학습률을 적응적 학습률이라고 한다.
적응적 학습률을 사용하는 대표적인 옵티마이저가 Adagrad와 RMSprop이다.
모멘텀 최적화와 RMSprop의 장점을 접목한 것이 Adam이다.
Adam 사용
모델을 컴파일할때 옵티마이저를 'adam'으로 설정하고 다시 훈련시켜보자!!
model= keras.Sequential()
model.add(keras.layers.Input(shape=(28,28)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - accuracy: 0.7722 - loss: 0.6645
Epoch 2/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8547 - loss: 0.4059
Epoch 3/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8716 - loss: 0.3556
Epoch 4/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 3s 2ms/step - accuracy: 0.8818 - loss: 0.3287
Epoch 5/5
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 4s 3ms/step - accuracy: 0.8869 - loss: 0.3070
<keras.src.callbacks.history.History at 0x7f21bb7f0770>
기본 옵티마이저를 사용한것보다 아주 조금 더 나은 성능을 보여준다.
검증 evaluate도 까먹지 말자/
model.evaluate(val_scaled, val_target)375/375 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.8779 - loss: 0.3374
[0.33696603775024414, 0.878083348274231]
검증에서도 조금 더 나은 점수가 나온다!
다음 글에서는 최고의 신경망 모델을 얻을 수 있게 해주는 도구들에 대해서 배워보자.
'DL' 카테고리의 다른 글
| DL/ 손실 곡선, 검증 손실, Dropout, 모델 저장, 콜백(ModelCheckpoint, EarlyStopping) (0) | 2026.01.29 |
|---|
